

PAGE CONTENTS
Objectives
The TANNDEM project aims to design and test a demodulator supported by an artificial neural network (ANN). This demodulator will be part of current communication standards such as 5G, DVB (Digital Video Broadcasting), Consultative Committee for Space Data Systems (CCSDS), and Internet of Things (IoT) for physical layer processing tasks: demodulation, de-mapping and channel decoding in satellite communication (Satcom) applications.
Within the demodulator, the Forward Error Correction (FEC) is the block that accounts from the most part of the computational complexity. FEC is a channel decoding scheme crucial to modern digital communications systems. Low-Density Parity-Check (LDPC), Reed-Solomon or Polar codes are examples of FEC algorithms used in different communications standards such as DVB or 3GPP (4G, 5G and future 6G). FEC decoding algorithms are typically the element of the receivers that require more complex computational capacity regarding resources. This computing problem is increased and aggravated in high data rate communications. Reducing the implementation complexity in communication receivers and the power consumption of FEC algorithms has become essential to evolving future communication systems to increase throughput. In addition to channel decoding, other physical layer tasks, such as demodulation and de-mapping, demand enormous resources in current communication receiver implementations. These resources can be the number of computations or processes to perform in each task, the computation time or the number of hardware components used in the implementation as logic gates.
From the point of view of satellite communications (Satcom), reducing power consumption and processing time is vital due to its repercussion on the payload size and, consequently, on the cost. To integrate with terrestrial networks, satellites must reduce latency and delay. Reducing the processing time favours the previous reduction or compensates for the least latency and delay innate to Satcom’s nature.
Benefits
The evolution of throughput towards high data rates in 5G for satellites with on-board regenerative payloads and, in the future 6G, requires the reduction of the resource and energy consumption in such tasks. In this work, we aim to reduce the receiver power consumption and computational complexity, while improving its throughput with artificial neural networks (ANNs). As illustrated in Figure 2, we aim at considering, trading off and assessing the implementation of the channel estimation, symbol demapping and decoding blocks powered by ANNs, to achieve the targeted Improvements of 85% computational complexity reduction, 10% power consumption reduction and 25% data rate increase.

Features
The TANNDEM team proposes ANN approach that could be DNN, CNN, RNN or GNN (or a combination of them) based on the data to be fed as input to the ANN model. The training algorithm employed in an ANN is critical in determining its performance. Therefore, the selected ANN model undergoes through weight and time complexity optimization using heuristic and metaheuristic-based training schemes to improve its performance and reduce its complexity. We have already started working in several examples of the independent functionalities to be able to unify them later on in the course of the project.
Example of demodulator based on NN:
The demodulator or receiver can uses PyTorch on Nvidia GPUs to train individual NNs evaluated by the Bit Error Rate (BER), which shows the rate of incorrectly recovered received bits after error correction. The individual performance of the NNs by inserting each NN in the OFDM receiver, while the rest of the processing is performed by the classical blocks. For the demapper, we use soft-demapping through an approximate LLR method implemented in MATLAB function. For the decoder, our proposal features a convolutional decoder (that decodes Binary Convolutional Coding (BCC)) implemented in MATLAB. For BER evaluation, the datasets can be implemented as:
Simulated dataset: WLAN toolbox in MATLAB R2020a to create a simulated dataset by generating 192k packets, each containing a random sequence of bits. These packets are then modulated in accordance with IEEE 802.11a standard with Modulation Coding Scheme (MCS) 16QAM 1/2, before passing through a simulated AWGN channel with desired SNR level. The SNR levels we use are between 2 dB and 24 dB with steps of 2 dB. With 192k total packets distributed among 12 SNR levels, we create a test set of 16k packets per SNR.
Over-The-Air (OTA) Dataset: Generate random bit sequences, modulate them according to IEEE 802.11a standard, and transmit them via Software-Defined Radios (SDRs) placed in an over-head ceiling-mounted array. We repeat this process with different power levels to account for different SNRs, and collect approximately 17k real-channel-distorted packets with SNRs between 11 to 24 dB, as our OTA test set.
Example of a NN-based channel estimator for ZP-OFDM system
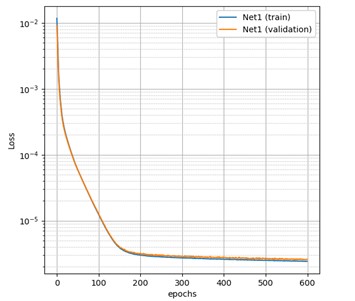
A feedforward neural network is proposed to refine the channel estimation obtained with the basic least squares (LS) channel estimator for a ZP-OFDM system. The neural has one hidden layer with hyperbolic tangent as activation function. Since the channel coefficients are complex, the NN input is the real-valued block version of the LS channel estimate in the frequency domain. The labels used for training consist of noisy versions of the actual channel responses in the frequency domain. Noisy versions are used to consider the uncertainty regarding the true channel response, which is difficult to obtain in practice. The NN is trained by minimizing the mean squared error (MSE) between the input and the label. The training set contains 3000 samples. The mini-batch size is composed by 50 samples, and 300 epochs are required to train the NN. The NN is trained for an ZP-OFDM system with 64 subcarriers, considering a signal-to-noise ratio (SNR) equal to 40 dB. As shown in below graph for SNR=40 dB, the NN converges to MSE = 0.5 x 10−4 in 300 epochs.
Challenges
|
Satellite communication has been playing a significant role in wireless communications due to its ability to offer omnipresent wireless coverage. In particular, low Earth orbit (LEO) satellites are able to enhance communication performance by reducing over-the-air delay and path loss due to the shorter link distance. Most commercial LEO Satcom systems are improving thanks to the third-generation digital satellite television broadcasts (DVB-S2/S2X). As 5G networks are developed, the interest in combining LEO satellites with 5G networks is growing. Nevertheless, to provide dual-mode communications using both satellites and terrestrial networks, DVB-S2X must incur high costs. Moreover, when compared to 5G, DVB-S2X lacks features like uplink synchronization, HARQ, and a control channel. Furthermore, the orthogonal frequency division modulation (OFDM) method can offer the bandwidths required for future space communication. For instance, as reported in, the Ku-band Starlink downlink is most likely based on OFDM. We then choose the 5G NR standard for the software demodulator’s implementation due to its higher flexibility and promising higher performance. Figure 1 illustrates a simplified conventional communication system for satellite communications. First, the desired bit stream is augmented by adding proper redundancy via channel coding. Then, the bits are mapped to symbols using quadrature amplitude modulation (QAM). This generates the waveform for the signal. This waveform is important because it is related to features such as power. Next, to address the interference related to the multipath nature of the propagation environment, the OFDM scheme is added. The signal is converted from the frequency domain to the time domain via the inverse fast Fourier transform (IFFT, and the cyclic prefix (CP) is added. Finally, the signal is transmitted. At the receiver side, shown in Figure 1, all the processes carried out on the transmitter side must be undone until we can recover the transmitted bit stream. During the training phase, pilot signals are sent to estimate the channel and then used in equalization during the data phase. 
Among the tasks mentioned above, channel estimation and equalisation, decoding and demodulation are the physical layer tasks that consume the most of the resources in a conventional receiver, such as power consumption. In addition, they require a large computation time and many operations. Accurate channel state information (CSI) is critical for the performance of wireless communication systems since this information is the basis for subsequent tasks such as adaptive modulation, beamforming, and other link adaptive technologies in the current modern systems. |
System Architecture
The implementation is carried out using MATLAB and Sionna Software, while the verification is carried out in Sionna for the SW part to successfully implement and test the ML algorithm and the associated measurement methodology, and with hardware-in-the-loop in a Xilinx Versal AI for realistic power consumption and complexity assessment.
- Detailed implementation schedule
- The detailed implementation schedule is explained in the following points:
- Design and Preparation: The first step, corresponding to the first month of the WP4, is dedicated to the investigation of the potential ML algorithms candidates. The design and preparation phase aims to inspect the available data that is needed to train our model and specify our ML model’s requirements. We use these requirements to design the architecture of the ML application, establish the serving strategy, and create a test suite for the future ML model. In addition, the Sionna implementation environment has to be set up. An HPC server account has to be created and the user has to increase the knowledge of the environment (e.g. Matlab scripts, parallel simulations etc).
- ML development and performance evaluation: In this second step, a simulation framework in Matlab is implemented to characterize the relevant key performance metrics of the decoder and to create the training data for the ML algorithm. The dataset is generated offline. Here, we run iteratively different steps, such as identifying or polishing the suitable ML algorithm for our situation and the relevant performance indicators, data generation and engineering, and model engineering. In ML development, multiple experiments on model training can be executed in parallel before deciding on what model is promoted. We specify the ML parameters and scripts, and training and testing data. The primary goal in this phase is to deliver a stable quality ML model. The goal of this part is to have an accurate dataset to train the ML algorithm. If needed, a High Computational Computing server is used. The dataset is reproducible and made available online.
- Data evaluation and analysis: The dataset obtained is used to obtain the accuracy data with ML implemented on Matlab. This phase is crucial in order to demonstrate the effectiveness of the proposed models and algorithms subject to the actual environmental variations. Extended data sets can be generated with the SIGCOM Labs facilities at these points after the exact system model has been defined in the MATLAB environment. We accurately quantize the accuracy of the model, using several key performance indicators (KPIs) to quantize the Performance, Power Consumption, and Complexity.
- Calibration and Profiling: Before the hardware implementation, the code is profiled and quantized using Sionna. Quantization makes it possible to use integer computing units and to represent weights and activations by lower bits, while pruning reduces the overall required operations. Profiling is needed to identify parts of the software that need to be accelerated. Once this step is completed, the algorithm is ready for hardware implementation.
- Proof of concept: The implemented software is implemented on the hardware using, on one hand, the Sionna implementation in GPU, and on the other hand, the AI acceleration chip from Xilinx (Versal AI) for realistic KPI evaluation on the complexity and power consumption. The obtained output is compared with the output obtained using the software only and the benefits of hardware implementation is demonstrated by comparing to known benchmarks (e.g. FPGA utilization, processing time in the GPU, etc). The exact KPIs is defined in due time during the project execution.
List and description of the facilities (hardware and software)
- Software
- Matlab (available on a local computer and centralized server at the university), Sionna implementation software,
- Sionna | 5G & 6G Physical Layer Research Software | NVIDIA Developer
- Vivado ML edition 2022.
- Sionna™ is a GPU-accelerated open-source library developed by NVIDIA for link-level simulations based on TensorFlow. It enables the rapid prototyping of complex communication system architectures and provides native support for the integration of neural networks. Sionna implements a wide breadth of carefully tested state-of-the-art algorithms that can be used for benchmarking and end-to-end performance evaluation. In TANNDEM, Sionna is used to test and validate the proposed models for the demodulator supported by ANN. Sionna is a powerful tool capable of implementing wide range of tested SOTA algorithm useful for doing benchmarking and performance evaluation in end-to-end wireless communication. This makes Sionna valuable tool for extensive physical layer research on 6G wireless communication system.
- The building blocks in Sionna are developed and extended continuously by the NVIDIA to carry-out wireless communication physical layer research. It supports a growing set of features, such as multi-user multiple-input multiple-output (MU-MIMO) link-level simulations with 5G-compliant low-density parity-check (LDPC) and Polar codes, 3GPP TR38.901 channel models, orthogonal frequency-division multiplexing (OFDM), channel estimation, and more. Every building block is an independent module that can be easily tested, understood, and modified according to your needs.
- Sionna provides a high-level Python application programming interface (API) to easily model complex communication systems while providing full flexibility to adapt to your research. Based on TensorFlow, Sionna scales automatically across multiple GPUs. Since Sionna is Tensorflow based platform, it provides Keras layers for complex communication architectures. As the components in Sionna are implemented as Keras layers, so it lets users build sophisticated system architectures by connecting the desired layers in the same way to build a neural network.
- The key features associated with the first release of the Sionna are:
- 5G LDPC, 5G polar, and convolutional codes, rate-matching, CRC, interleaver, scrambler
- Various decoders
- QAM and custom modulation schemes
- 3GPP 38.901 Channel Models (TDL, CDL), Rayleigh, AWGN
- OFDM
- MIMO channel estimation, equalization, and precoding
Hardware
- The implementation steps is organised along the 8 months planned for WP4 in the project in such a way that the hardware SIGCOM lab facilities are available. The training data generation, algorithm simulation, and results collection take most of the planned timeline. A detailed list of the implementation steps, equipment and time effort needed is prepared in due time, together with a traceable verification and test plan, including an accurate description of the measurement tests.
- The summarized list and description of the facilities (hardware) available at SnT are as follows:
- Centralized high-performance computers and servers at SnT (“regular” nodes: Dual CPU, no accelerators, 128 to 256 GB of RAM.
- “GPU” nodes: Dual CPU, 4 Nvidia accelerators, 768 GB RAM, preferable- NVIDIA RTX A6000 workstation GPU: It has specs, technology, and bundled software to ignite performance in any workstation’s inner workings. The RTX A6000 has 10,752 CUDA cores, 84 RT cores, and 336 Tensor cores to provide general graphics processing speed and increased speed and number of ray tracing and AI inference operations. It also has a massive 48GB of RAM and a 768 GB per second peak memory bandwidth. You can even link two RTX A6000s together with NVLink. The RTX A6000 supports high dynamic range (HDR), and can output to up to four monitors simultaneously.
- “bigmem” nodes: Quad-CPU, no accelerators, 3072 GB RAM
- Versal AI Core Series VCK190 evaluation kit: This chipset from
- Xilinx is a perfect blend of adaptive signal processing and ML, capable of targeting ML focussed signal processing applications. In terms of performance, it is at the top of the food chain.
- Versal AI Core Series VCK5000: The VCK5000 also known by DPUCVDX8H is a high throughput and high performance NN processing engine by Versal AI core. It supports Vitis-AI development environment capable of accelerating AI interface on Xilinx hardware platform. The VCK5000 enables high efficiency and it unleashes the full potential of AI acceleration on Xilinx chips. The general hardware analysing of the float-based CNN model requires highly intensive computation requiring high bandwidth of memory for the low latency and high throughput of the operation. Therefore, the quantization is employed to achieve high performance with less computation and memory. The quantization allows representation of weights and activations with lower bits integer computing units.
Plan

The work to be performed in each WP is summarized below:
WP 1.0: Literature Review and Application Scenario Definition
Objective: definition of the application into which the demodulator is integrated, SoTa review and establish the end-user requirements and quantify the advantages of using the new demodulator with respect to SoTA alternatives.
Output: TN 1 is composed of TN1.1 and TN 1.2.
WP 2.0: Technical Baseline and Design
Objective: identification of the technical baseline that offers the best potential for the development of a demodulator based on an artificial neural network (ANN). To do so, preliminary simulations based on technological options are foreseen to select the best ANN topology that it can satisfy the technical requirements.
Output: TN 2 is composed of TN2.1 and TN 2.2.
WP 3.0: Definition Plan of Demodulator
Objective: focused on all detailed plans necessary to successfully implement and test the deliverable items and verify their compliance with the technical specifications.
Output: TN 3.
WP 4.0: Development and Testing of Demodulator
Objective: development of the SW related to the demodulator, followed by the testing campaign and the reflection and analysis of the results. It is the longest WP in this activity as it also includes a final task where compliance with requirements and potential corrective actions are considered. Therefore, we foresee this task to take a significant portion of the total project time
Output: TN 4 is composed of TN4.1 and TN 4.2.
WP 5.0: Outline and technology
Objective: a critical assessment of the potential of the developed items for commercial exploitation and establishes a development plan to further raise their TRL and thereby bring them to market readiness. Disseminate the findings and identify the technical, non-technical and standardization gaps that exist for implementing and commercialize the demodulator developed and tested in WP 3 and 4. Propose how these gaps should be addressed and develop a roadmap of key workstreams, activities and outputs.
Output: TN 5.
WP 6.0: Project Management
Objective: It is dedicated throughout the project to the management, coordination of the different tasks, dissemination, documentation, and project meetings.
Output: FP, FR.
Current Status
As of November 2023, the TANNDEM project is working on its WP1 with definition of the scenarios and requirements, definition of the ML algorithms and their framework, generation of the training data sets, and selection of the AI chipset family.
The team will work towards the defining of the ML algorithms in the WP2 of the project.